
Address validation, also called as address verification, is a process for verifying the accuracy of postal information. The verification of address are crucial for corporations that utilize both domestic and global markets. Address verification also enables confirmation that the address data collected is valid, up to date, and standardized for the region. Solutions in address verification not only correct spelling, ensure proper address formatting, and append missing information, but also function in real time to verify details and corresponding information to be factual.
By confirming address data from all your sources —on your website, your CMS, in call centers, or existing addresses in your system—you can guarantee the data you have is clean and complete for use. Which, in turn, will streamline customer service and brand satisfaction during digital onboarding, enabling deeper data-driven decisions, and reduced costs in unnecessary expenses.
How is the address verified?
While your customer provides their complete address for verification, typically only the numeric portion of the address is validated by the system. The house number and ZIP/postal code are matches to the database. This causes some confusion every time a customer inputs an number for an apartment or suite that is not related to the pincode/postal information. If the system can’t get an exact match, it reverts values that denotes at which phase the address verification failed. So further manual assistance is required to verify the details.
Complex address systems over various formats and its verification have continued to be a big riddle for technology companies. Typically address verification is still done manually by matching the address mentioned in the identity document with the address filled in any kind of application form filled by the customer.
Companies grapple with a wide variety of fraudulent activities where some users rig addresses to avail discounts or commit a fraud, and manual checks involving human resource can be a huge operational cost and error prone for the companies. This has been a major pain point for e-commerce companies which bank on the last-mile logistics and ultimately bleed revenues. That is why address verification must be given impetus during the very initial step of identity verification process.
We have taken a novel approach to solve this issue by building a unique Address Net Model to match the address in the identity documents with the address in an application form. We have used state of the art deep learning models to identify different components from the address strings automatically.
What are the unique features of the Address Verification model: –
- State of the art NLP and deep learning models are used to identify address components like street, route, premise, district, city, pin code, etc.
- Once components are identified, then a match score is calculated based on custom weights assigned to different components of addresses. The weights are flexible and can be changed based on different use cases and the importance of different components.
Data pre-processing and the scoring Logic in Address Verification Model
- Various data pre-processing steps are considered before calculating the match-score to ensure best/unbiased/error free match-score.
- Spell mistakes are rectified with unique approach using phonetic match and fuzzy match algorithms. This ensures small spelling mistakes in the address are not penalized heavily while calculating the match score.
- Synonyms are treated separately for regional terms in each country, e.g. Kota(city), Kecamatan (District), etc. in the scoring logic and given weights accordingly in scoring.
- Prefixes and suffixes are removed before scoring is done to ensure most effective address match score.
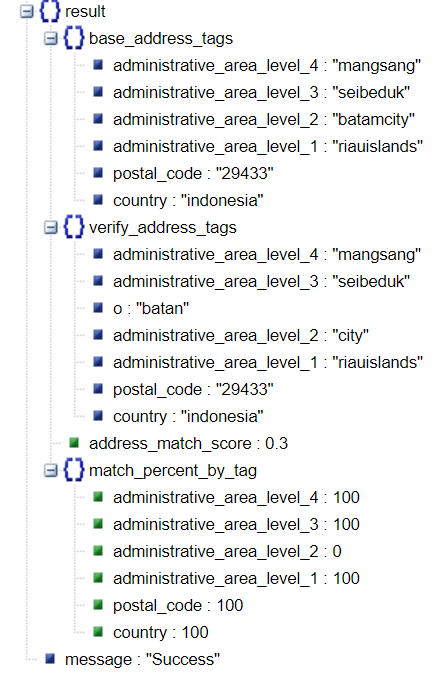
Post component identification and data pre-processing, an overall address match score and a component wise match score is calculated for the two address strings.
The component wise match score gives the end user a flexibility to assign own custom rules on different components as per their use case and requirements, for example: an e-commerce company would like to give more weight to last mile address components like premise, sub-premise, house no. etc.
Try our 6-months free e-KYC solution now.

Raghav Agrawal is a Senior Data scientist at IDCentral. He is a graduate from IIT Delhi and has been working as Machine Learning specialist for 7+ years. He has played pivotal role in some big Indian startups like Policybazaar and Cointribe where he developed solutions around Credit risk scoring, automated underwriting and risk modelling. He has also worked as a Senior consultant with Accenture in their Advance Analytics division where he served large banking clients in some transformational analytics projects.
 Blog
Blog Webinars
Webinars Whitepapers
Whitepapers Infographics
Infographics Identity Dictionary
Identity Dictionary Frequently Asked Questions
Frequently Asked Questions